Digital Newsletter
Each week our editor Phil Alsop rounds up the most popular articles, videos and expert opinions. We compile this into a Digital Newsletter and send it straight to your inbox every week.
Digital Magazines
We'll let you know each time a new edition of Digitalisation World is released so that you're always kept up-to-date with the latest and greatest news and press releases.
Video Magazines
The Digitalisation World Video magazine contains the latest Zoom interviews with experts in the industry.
If your organisation has a data centre, it is likely AI technology will be deployed into it soon. Whether the AI system will be a chat bot, provide the automation of processes across multiple systems, or enable the analysis of large data sets, this new technology promises to accelerate and improve the way many companies do business. However, AI can be a confusing and misunderstood concept. In this article we’ll explore five fundamental things you should know about how AI networking works and the unique challenges the technology faces.
1. A GPU is the brain of an AI computer
In simple terms, the brain of an AI computer is the graphics processing unit (GPU). Historically, you may have heard that a central processing unit (CPU) was the brain in a computer. The benefit of a GPU is that it is a CPU that is great at performing math calculations. When an AI computer or deep learning model is built, it needs to be “trained,” which requires solving mathematical matrices with potentially billions of parameters. The fastest way to do this math is to have groups of GPUs working on the same workloads, and even then, it can take weeks or even months to train the AI model. After the AI model is built, it is moved to a front-end computer system and users can ask questions of the model, which is called inferencing.
2. An AI computer contains many GPUs
The best architecture to solve AI workloads is to use a group of GPUs in a rack, connected to a switch at the top of the rack. There can be additional racks of GPUs all connected in a networking hierarchy. As the complexity of the problems being solved increases, the greater is the need for GPUs with the potential for some implementations containing clusters of thousands of GPUs. Picture the common image of a data centre with rows and rows of computing racks.
3. An AI cluster is a mini network
When building an AI cluster, it is necessary to connect the GPUs so they can work together. These connections are made by creating miniature computer networks that allow the GPUs send and receive data from each other.
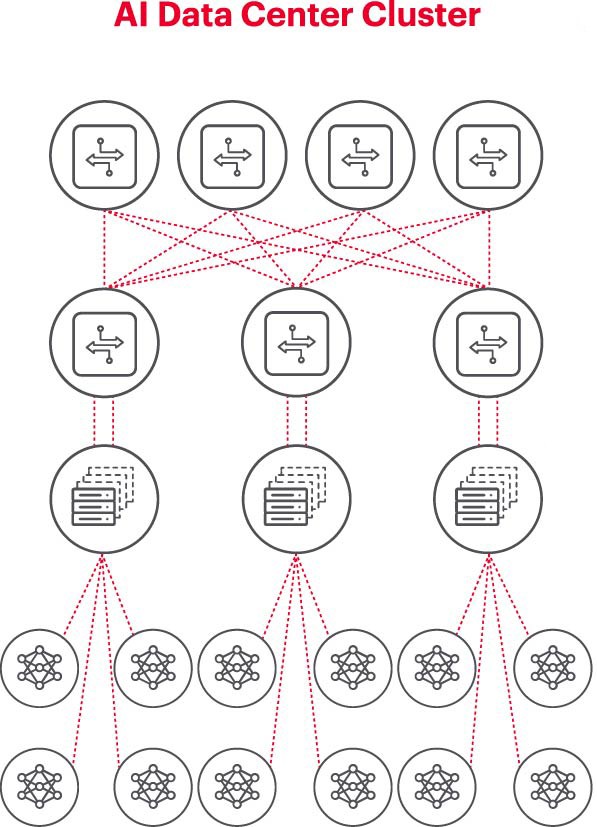
Figure 1. An AI Cluster
Figure 1 illustrates an AI Cluster where the circles at the very bottom represent workflows running on the GPUs. The GPUS connect to the top-of-rack (ToR) switches. The ToR switches also connect to network spine switches at the top of the diagram, demonstrating a clear network hierarchy required when many GPUs are involved.
4. The network is the bottleneck of AI deployments
Last fall, at the Open Compute Project (OCP) Global Summit, where participants were working out the next generation of AI infrastructure, a key issue that came up was well articulated by Loi Nguyen from Marvell Technology: the “network is the new bottleneck”
GPUs are very effective at solving math problems or workloads. The fastest way for these systems to accomplish a task is to have the GPUs all collaborate on the same workload in parallel. To do this, the GPUs need the information that they will work on, and they need to communicate with one another. If a GPU does not have the information it needs, or it takes longer to write out the results, all the other GPUs must wait until the collaborated task is complete.
In technical terms, the prolonged packet latency or packet loss contributed by a congested network could cause retransmission of packets and significantly increase the job completion time (JCT). The implication is that there can be millions or tens of millions of dollars of GPUs sitting idle, impacting bottom line results and potentially affecting time to market for companies seeking to take advantage of the opportunities coming from AI.
5. Testing is critical for successfully running an AI network
To run an efficient AI cluster you need to ensure that GPUs are fully utilised so you can finish training your learning model earlier and put it to use to maximise return on investment. This requires testing and benchmarking the performance of the AI cluster. However, this is not an easy task as there are many settings and interrelationships between the GPUs and the network fabric which should complement each other architecturally for the workloads.
This leads to many challenges in testing an AI network:
- The full production network is hard to reproduce in a lab due to cost, equipment availability, skilled network AI engineer time, space, power, and heat considerations.
- Testing on a production system reduces available processing capabilities of the production system.
- Issues can be difficult to reproduce as the types of workloads and the data sets can be widely different in size and scope.
- Insights into the collective communications that happens between the GPUs can be challenging as well.
One approach to meeting these challenges is to start by testing a subset of the proposed setup in a lab environment to benchmark key parameters such as JCT, the bandwidth the AI collective can achieve, and how that compares to the fabric utilisation and buffer consumption. This benchmarking helps find the balance between GPU / workload placement and network design/settings. When the computing architect and network engineer are reasonably pleased with the results, they can apply the settings to production and measure the new results.
Conclusion
In order to take advantage of AI, the devices and infrastructure of the AI network need to be optimised. Corporate research labs and academic settings are working on analysing all aspects of building and running effective AI networks to solve the challenges of working on large networks, especially as best-practices are continuously evolving. It’s only through this reiterative, collaborative approach that the industry can achieve the repeatable testing and agility in experimenting “what-if” scenarios that is foundational to optimising the networks that AI is built upon.